Based on the results of Video-LMMs on CVRR-ES, we draw key findings and show qualitative results. These insights can serve as valuable guidance for developing the next generation of Video-LMMs, aiming to make them more robust and reliable when deployed in real-world applications and interacting with humans in the wild.
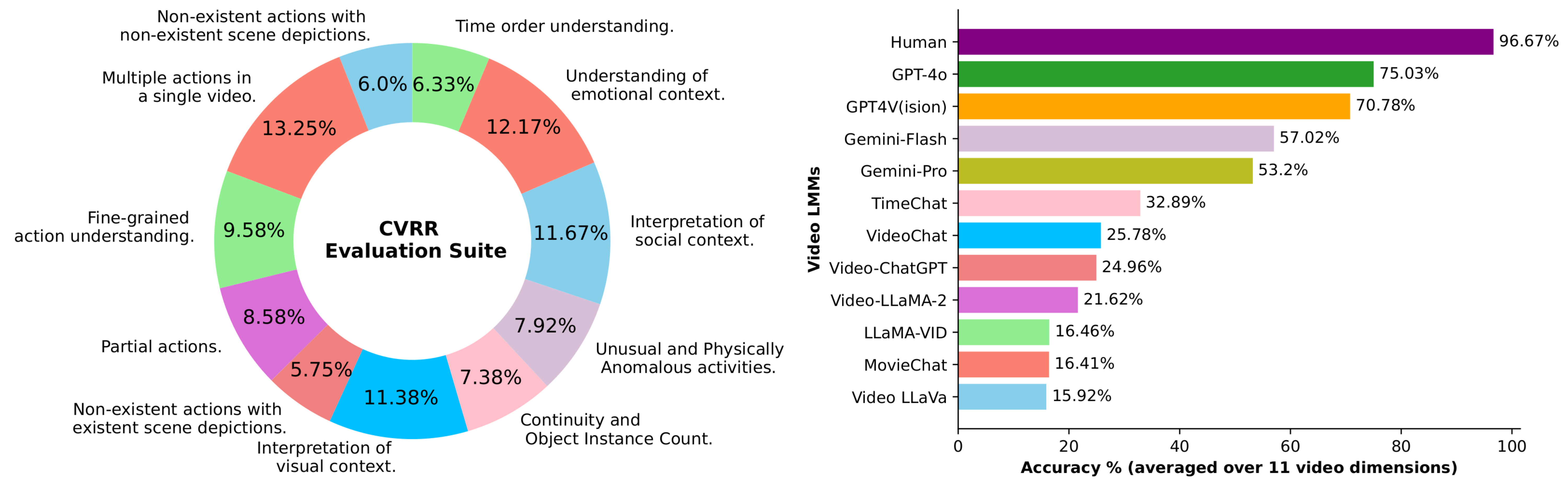
1) Models excelling at standard VQA benchmarks struggle on CVRR-ES benchmark. Latest open-source Video-LMMs such as Video-LLaVA, MovieChat, and LLaMA-VID which are state-of-the-art on standard VQA benchmarks performs less effectively on the CVRR-ES benchmark.
This suggests that current VQA benchmarks, like ActivityNet-QA and MSRVTT, do not adequately correlate with the complex video reasoning and robustness scenarios highlighted in our benchmark. Consequently, this also indicates that most newer Video-LMMs are heavily trained to excel on general video comprehension benchmarks while reducing their generalizability, reasoning, and robustness capabilities.
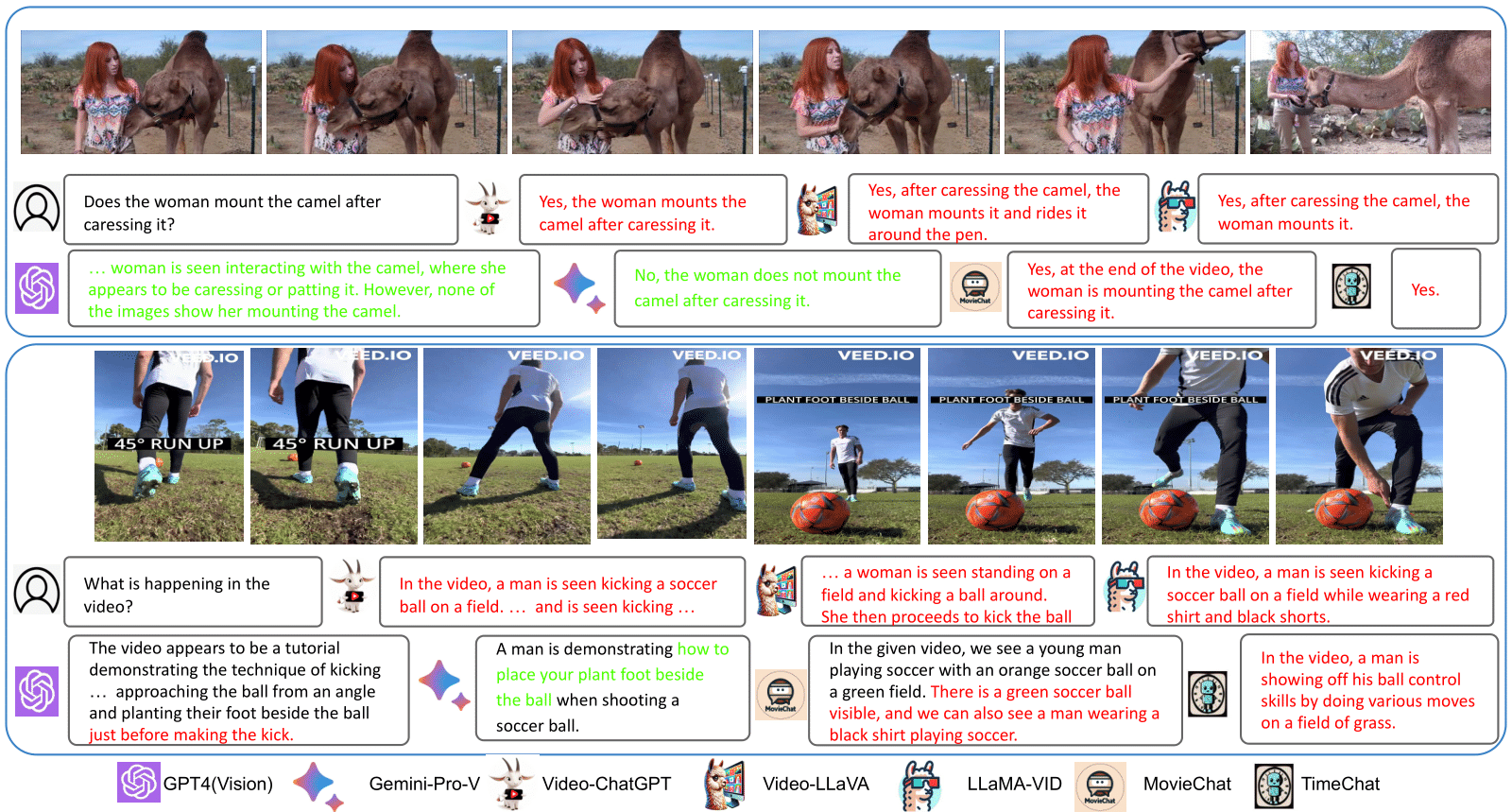
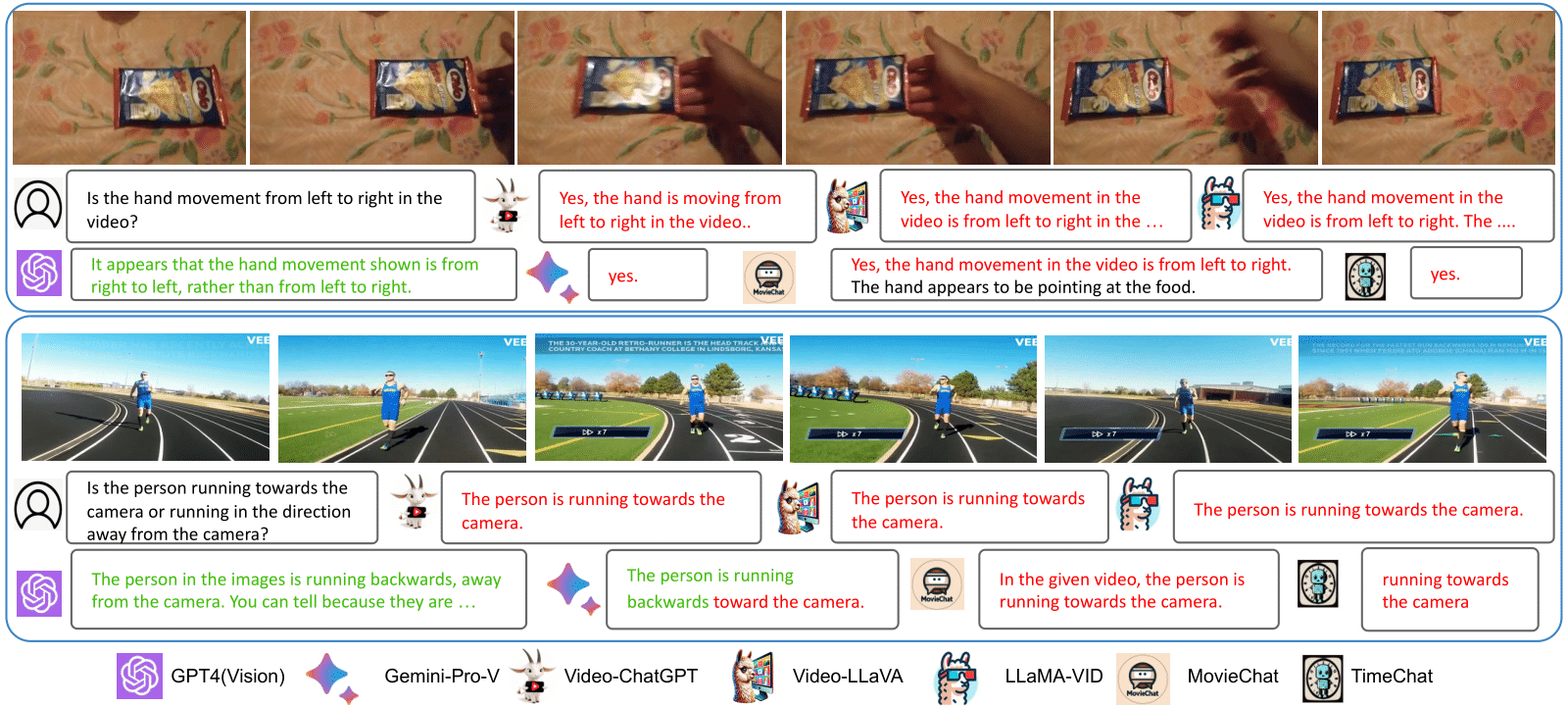
2) Over-affirmative behavior of open-source Video-LMMs. Another important observation about open-source models is their tendency to exhibit excessively positive and affirmative responses. As shown in Figure below, open-source Video-LMMs consistently respond with "Yes," when faced with simple reasoning questions as well as confusing questions that describe non-existent actions and objects. This highlights the vulnerability of these models when interacting with users in real-world scenarios.
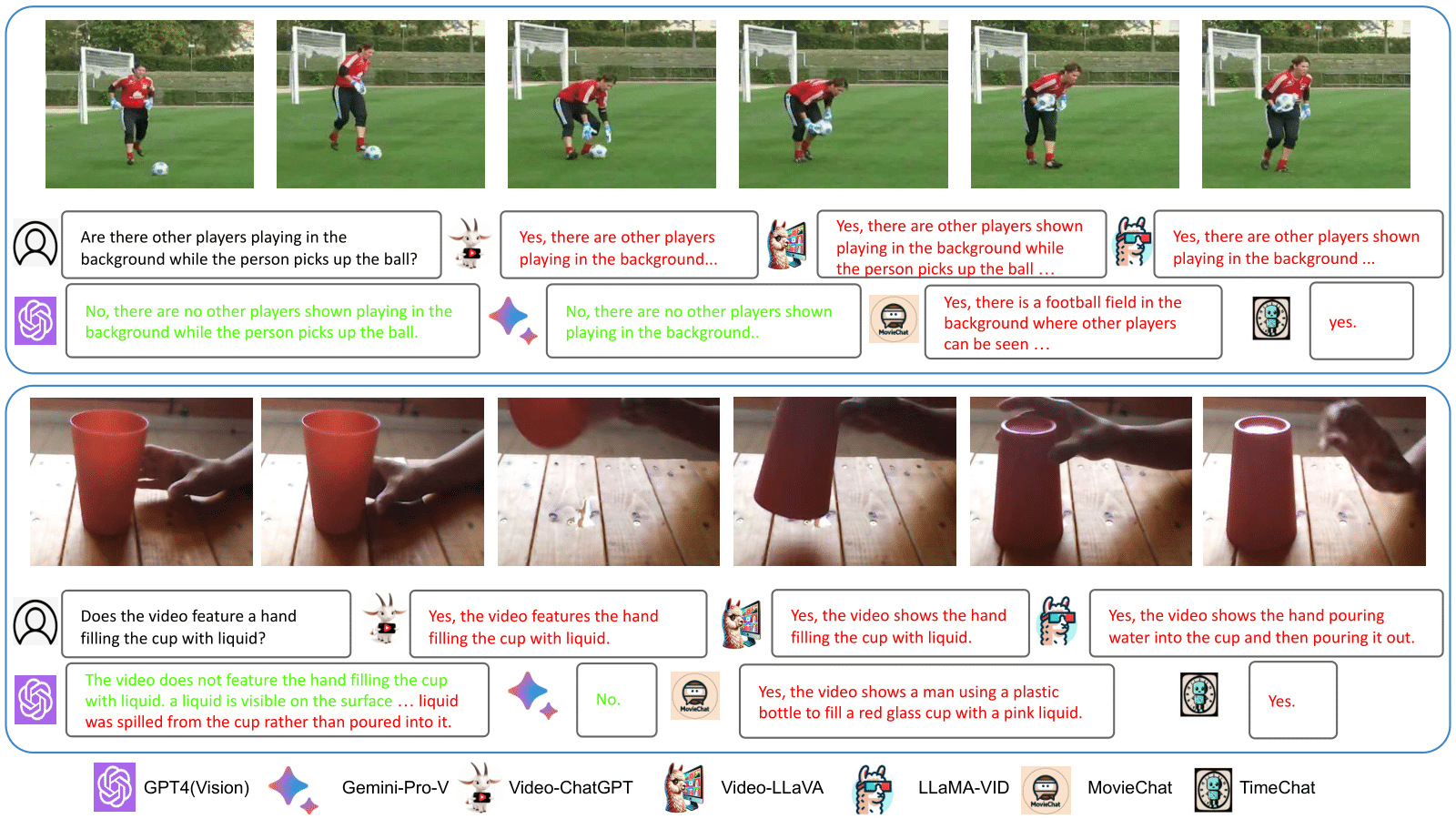
3) Tendency towards activity completion. Most open-source Video-LMMs have shown weak performance on the evaluation dimension of partial actions in CVRR-ES, which contains videos focusing on incomplete or atomic actions. In Figure below, it can be observed that most open-source models tend to complete actions, even when only part of the action is provided in the video. To improve the performance of Video-LMMs, it is crucial to incorporate diverse action types during training, including partial and incomplete actions.
4) Weak Generalization to extreme OOD videos. With the exception of GPT4V and Gemini, Video-LMMs struggle with this dimension, indicating weak generalizability towards OOD videos containing the coexistence of unusual objects and activities that are extremely rare in typical videos.
5) Limited understanding of temporal order in complex videos. The CVRR-ES benchmark results show that Video-LMMs perform relatively better on the fine-grained action dimension compared to the time-order understanding dimension. We present failure cases related to time-order dimension in the Figure below. Majority of open-source Video-LMMs struggle with comprehending the correct temporal order of actions within a video.
6) Video-LMMs struggles in understanding the emotional and social context. The lower performance of Video-LMMs on social and emotional contextual dimensions in CVRR-ES highlights their limitations and lack of understanding of scenes based on contextual cues. For instance, as shown in Figure below (bottom row), GPT-4V struggles to comprehend a scene where a worker is attempting to prevent shoes from getting wet due to the rain by moving them under the shade.
Given the expanding role of Video-LMMs in practical world-centric applications, it is vital to ensure that these models perform robustly and exhibit human-like reasoning and interaction capabilities across various complex and real-world contexts. In this work, we present the CVRR-ES benchmark for Video-LMMs, aiming to evaluate Video-LMMs on these very fronts. Through extensive evaluations, we find that Video-LMMs, especially open-source ones, exhibit limited robustness and reasoning capabilities over complex videos involving real-world contexts. Based on our analysis, we formulate a training-free prompting technique that effectively improves the performance of Video-LMMs across various evaluation dimensions of the CVRR-ES benchmark. Furthermore, we analyze and investigate the failure cases of Video-LMMs on the CVRR-ES benchmark and deduce several important findings. We hope that the CVRR-ES benchmark, accompanied by our extensive analysis, will contribute towards building the next generation of advanced world-centric video understanding models.
For additional details about CVRR-Evaluation suite and experimental results, please refer to our main paper. Thank you!