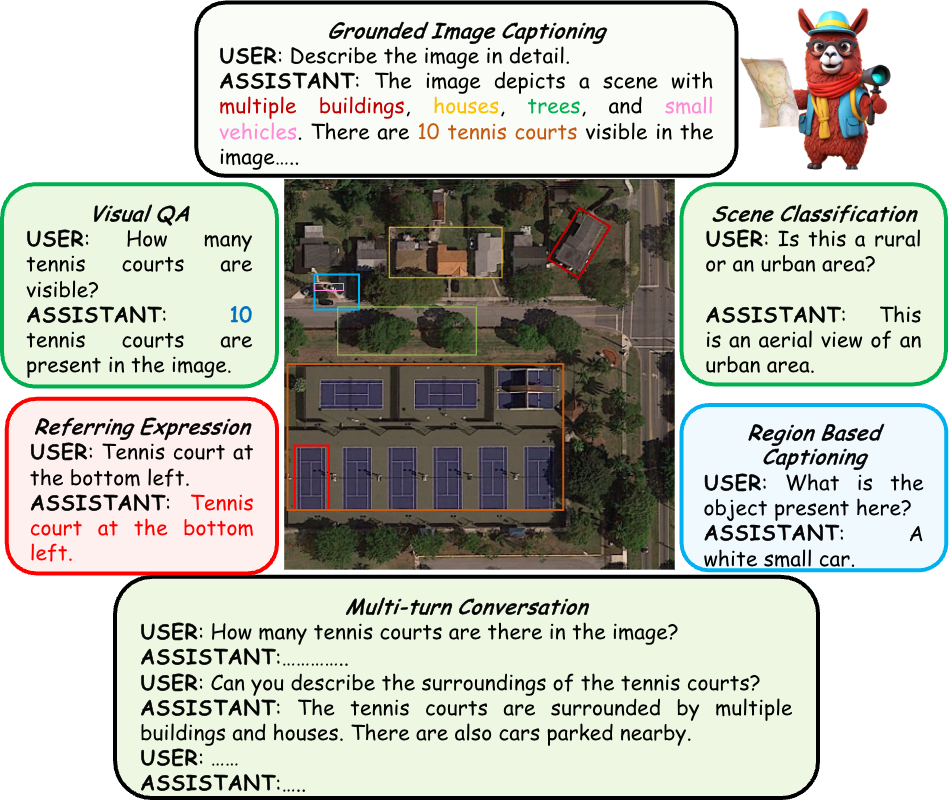
GeoChat can accomplish multiple tasks for remote-sensing (RS) image comprehension in a unified framework. Given suitable task tokens and user queries, the model can generate visually grounded responses (text with corresponding object locations - shown on top), visual question answering on images and regions (top left and bottom right, respectively) as well as scene classification (top right) and normal natural language conversations (bottom). This makes it the first RS VLM with grounding capability.
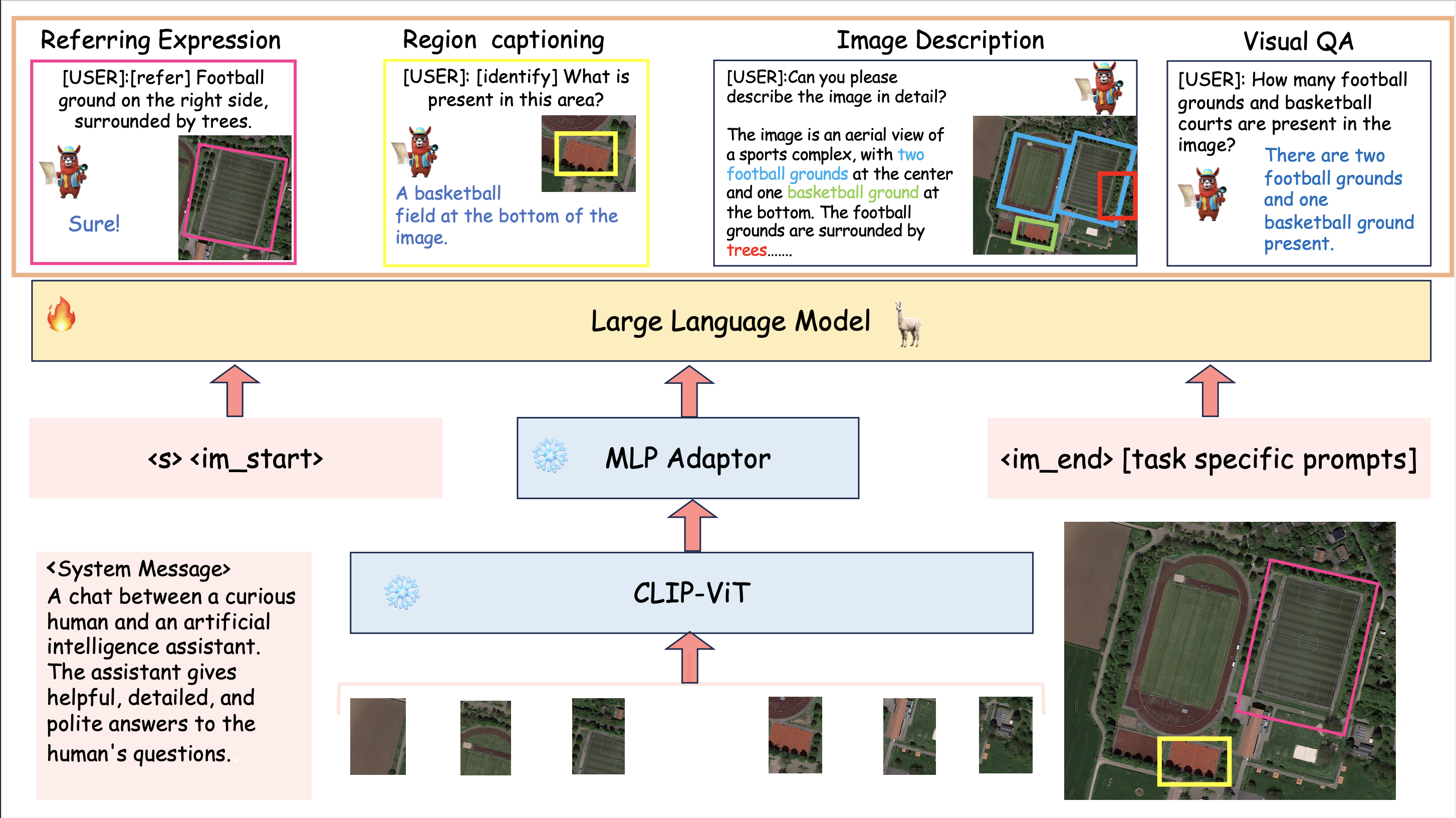
An overview of GeoChat - the first grounded large vision-language model for remote sensing. Given an image input together with a user query, a visual backbone is first used to encode patch-level tokens at a higher resolution via interpolating positional encodings. A multi-layer perceptron (MLP) is used to adapt vision-tokens to language space suitable for input to a Large Language Model (Vicuna 1.5). Besides visual inputs, region locations can also be input to the model together with task-specific prompts that specify the desired task required by the user. Given this context, the LLM can generate natural language responses interleaved with corresponding object locations. GeoChat can perform multiple tasks as shown on top e.g., scene classification, image/region captioning, VQA and grounded conversations.
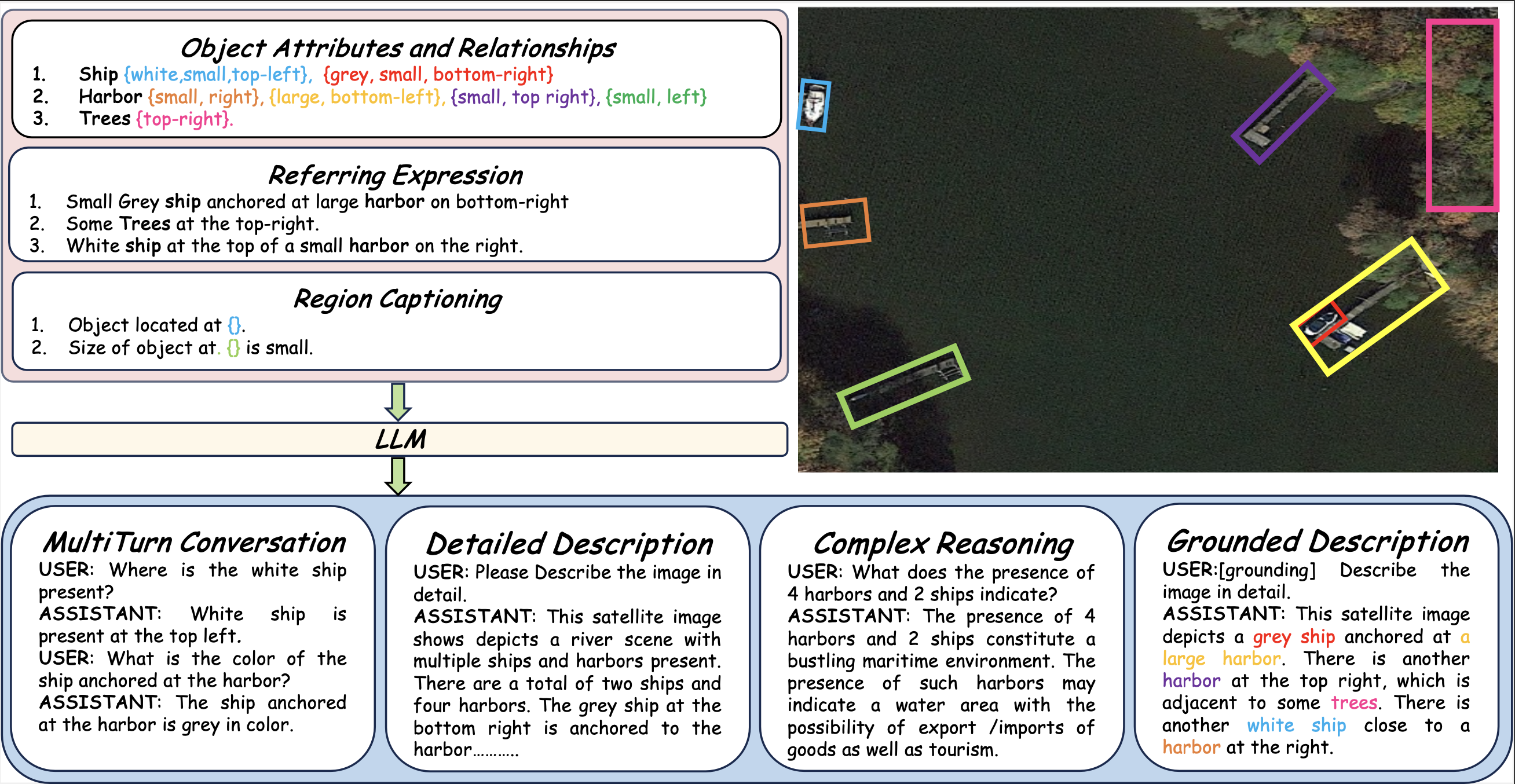
Types of annotations available in the GeoChat instruction-set. For a given RS image, we obtain object attribute and relationship information, referring expressions and region captions along with their corresponding region annotations (shown over the image). This structured information is used to create the rich instruction-set with a total of 318k image-instruction pairs.
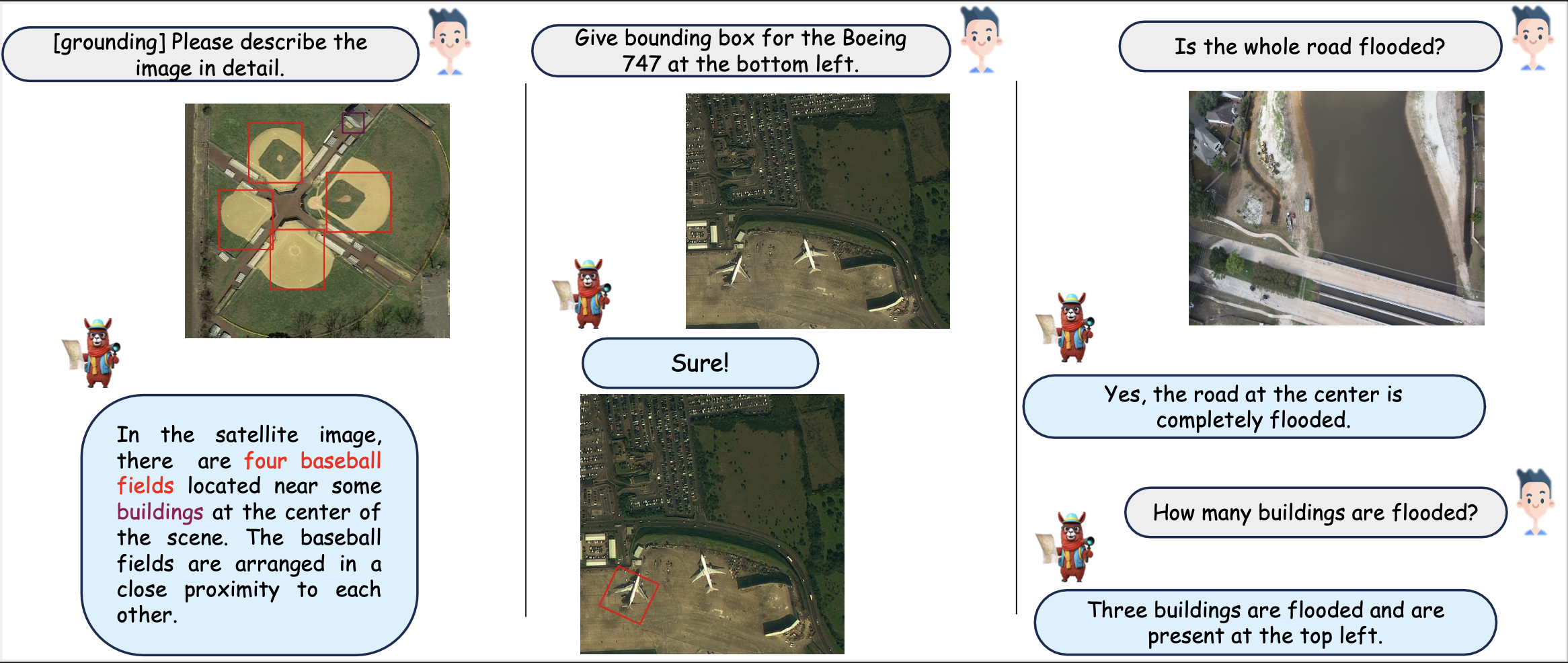
Qualitative results of GeoChat. (left-right) Results are shown on grounding, referring object detection, and disaster/damage detection. The user can provide task-specific tokens (e.g., [grounding]) to shape model responses according to the desired behavior. The model can generate textual responses (right), only visual grounding (center) and both text and object groundings interleaved together (left). The model can also specify object types, object counts, object attributes and object relationships.
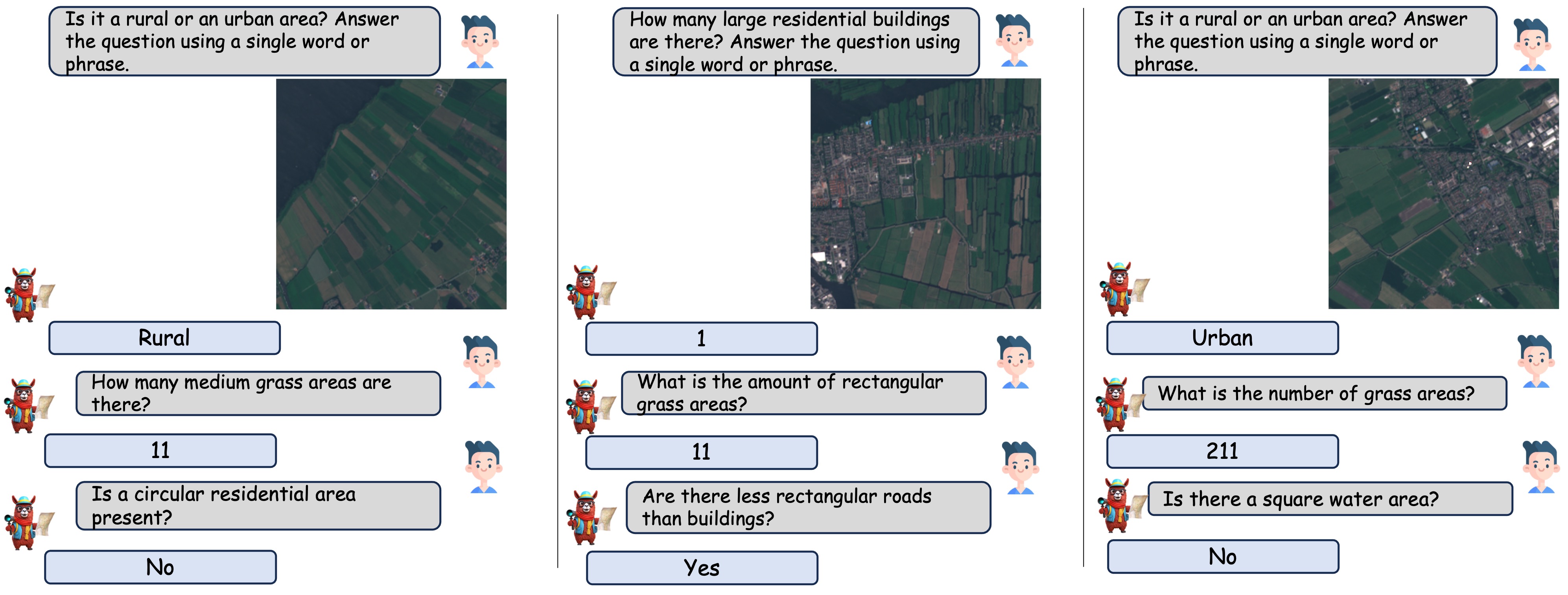
GeoChat is able to hold multi-turn conversations, based on various types of questions, including presence, count, complex comparisons and so on. It is able to detect objects and hold conversations against low resolution images as well.
| Method | Presence | Comparison | Rural/Urban | Avg. Accuracy |
| LLaVA-1.5 | 55.46 | 68.20 | 59.00 | 62.77 |
| Qwen-vl-Chat | 38.57 | 67.59 | 61.00 | 55.35 |
| MiniGPTv2 | 55.16 | 55.22 | 39.00 | 54.96 |
| RSVQA | 87.47 | 81.50 | 90.00 | 86.32 |
| EasyToHard | 90.66 | 87.49 | 91.67 | 89.94 |
| Bi-Modal | 91.06 | 91.16 | 92.66 | 91.63 |
| SHRNet | 91.03 | 90.48 | 94.00 | 91.84 |
| RSGPT | 91.17 | 91.70 | 94.00 | 92.29 |
| GeoChat | 91.09 | 90.33 | 94.00 | 90.70 |
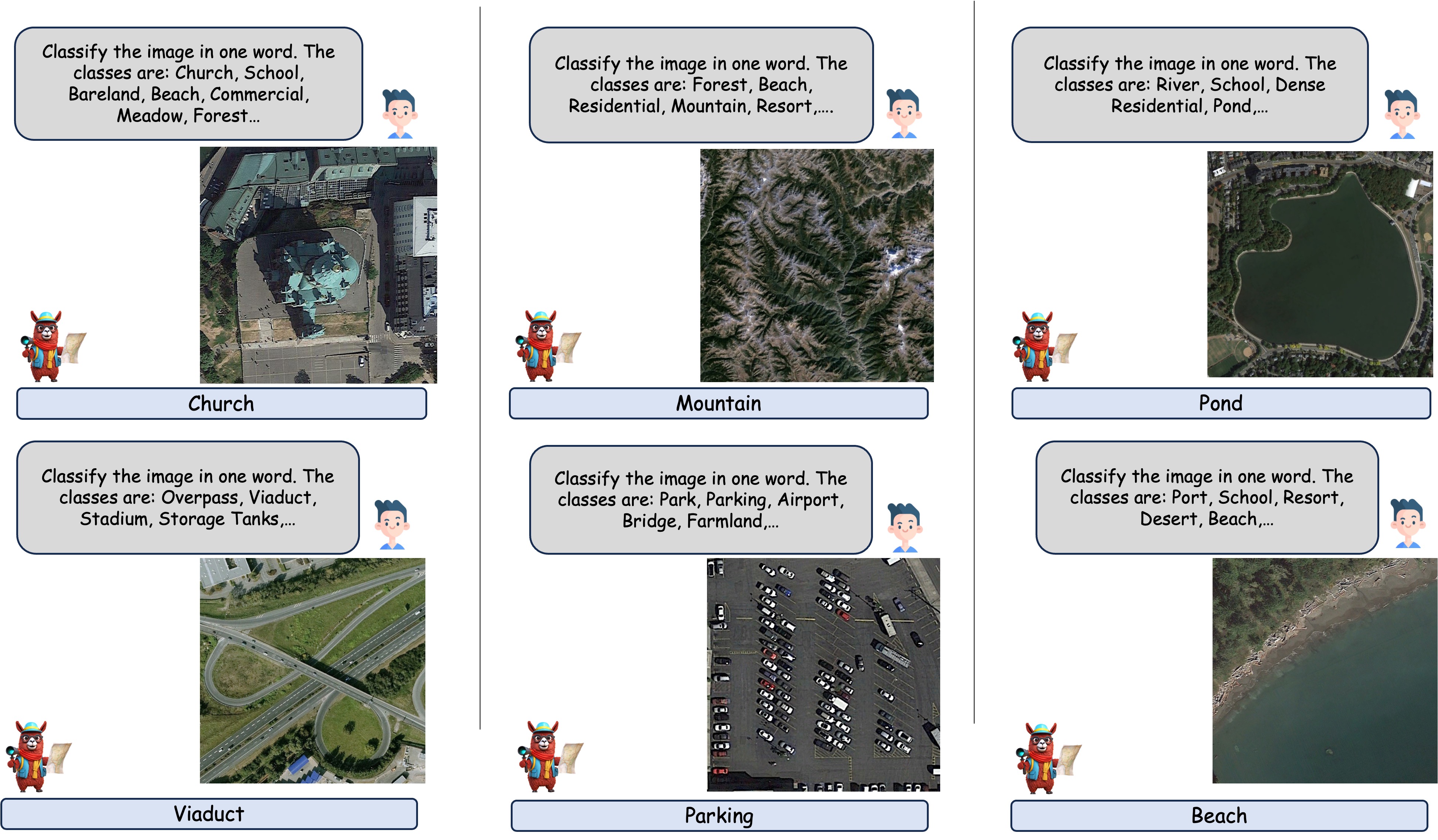
For scene classification, the model is presented with a list of dataset classes in the input prompt and tasked with selecting a single class from the provided options.
| Model | UCMerced | AID |
| Qwen-VL | 62.90 | 52.60 |
| MiniGPTv2 | 4.76 | 12.90 |
| LLaVA-1.5 | 68.00 | 51.00 |
| GeoChat | 84.43 | 72.03 |
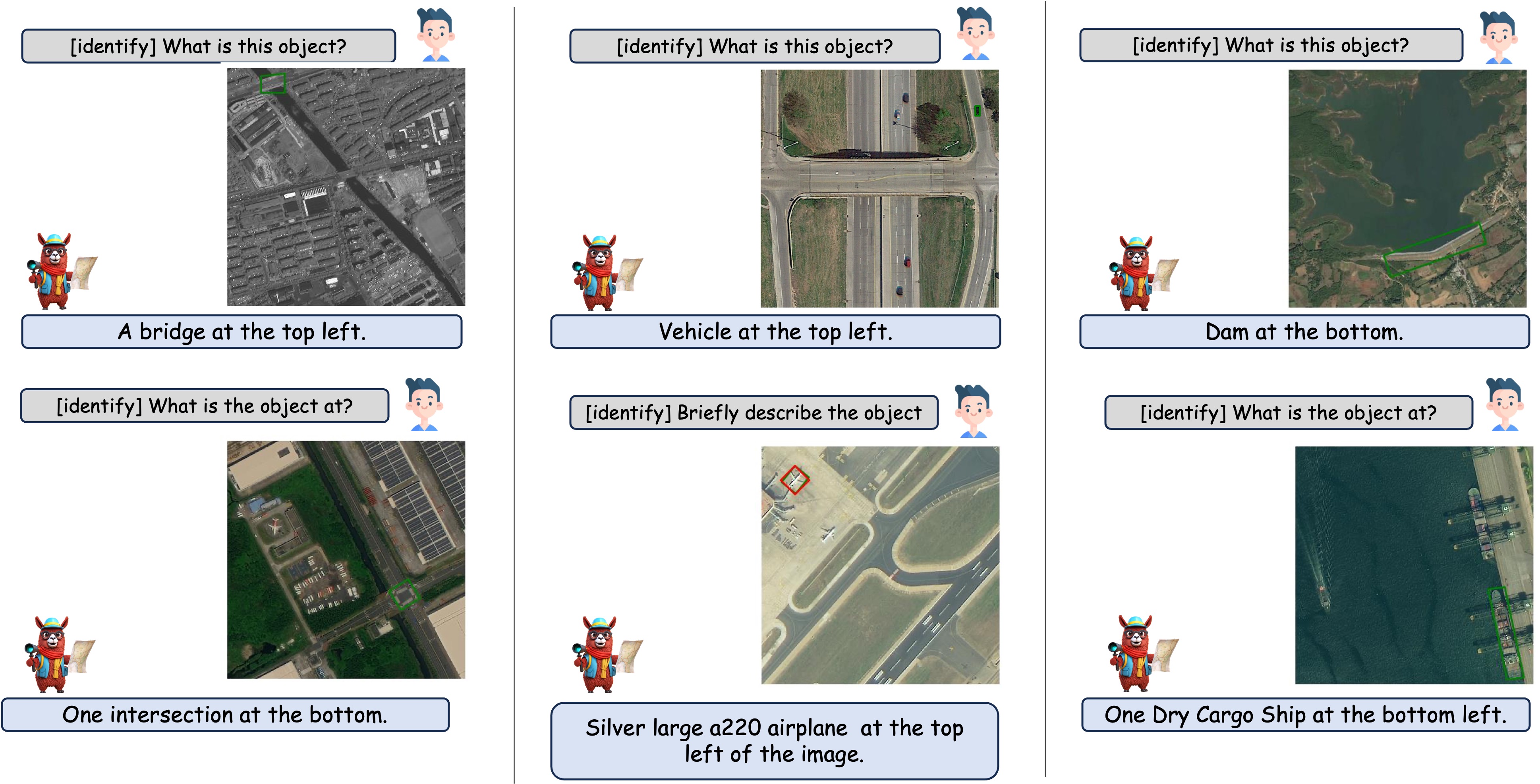
Given a bounding box, GeoChat is able to provide brief descriptions about the area or the object covered by the bounding box.
| Model | ROUGE-1 | ROUGE-L | METEOR |
| MiniGPTv2 | 32.1 | 31.2 | 10.0 |
| GeoChat | 87.3 | 87.2 | 83.9 |
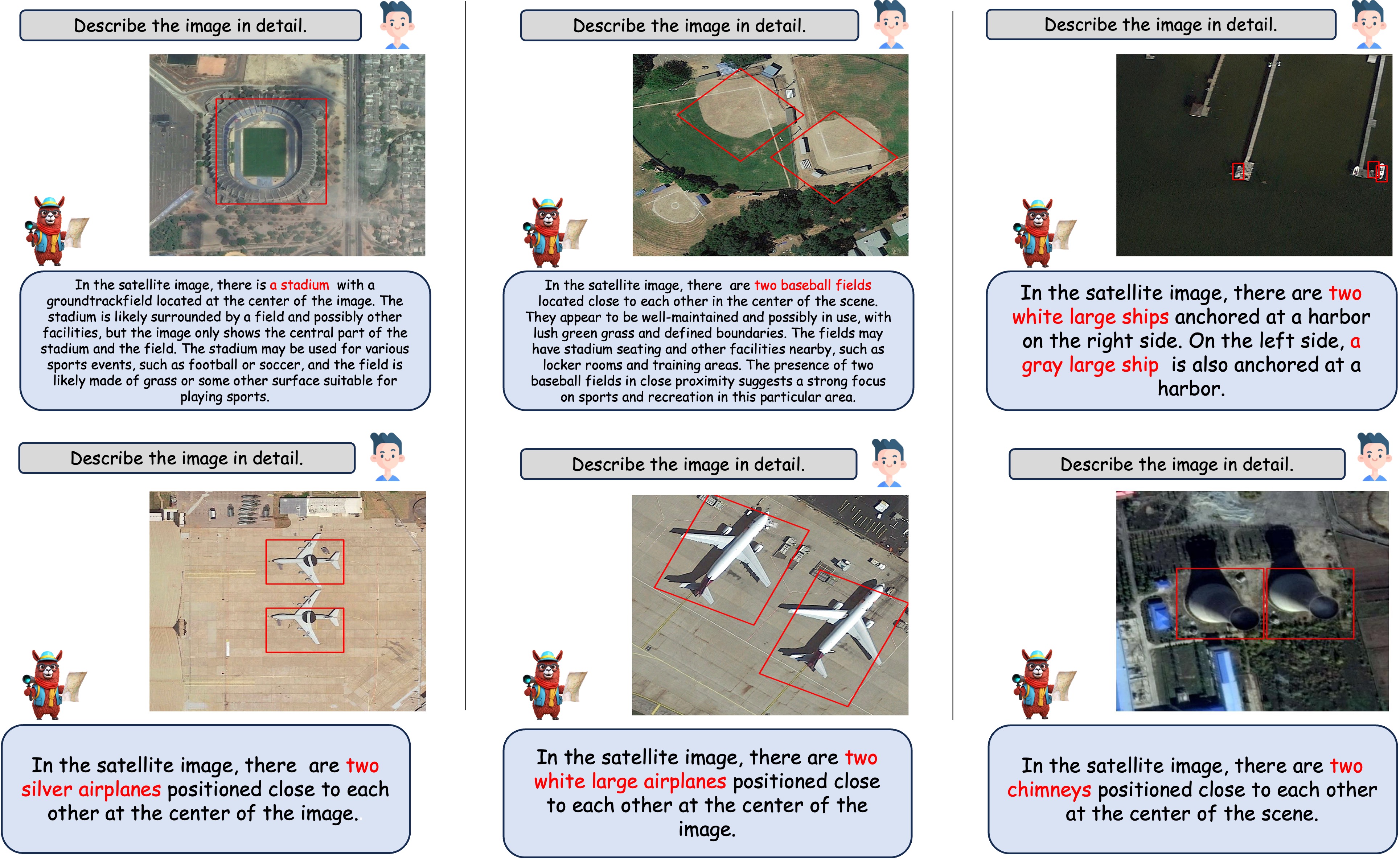
When asked to describe the image with the special token '[grounding]', GeoChat outputs both the description of the image as well as the bounding boxes for all the objects detected.
| Model | acc@0.5 | acc@.25 | METEOR |
| MiniGPTv2 | 10.8 | 30.9 | 16.4 |
| GeoChat | 11.7 | 33.9 | 48.9 |
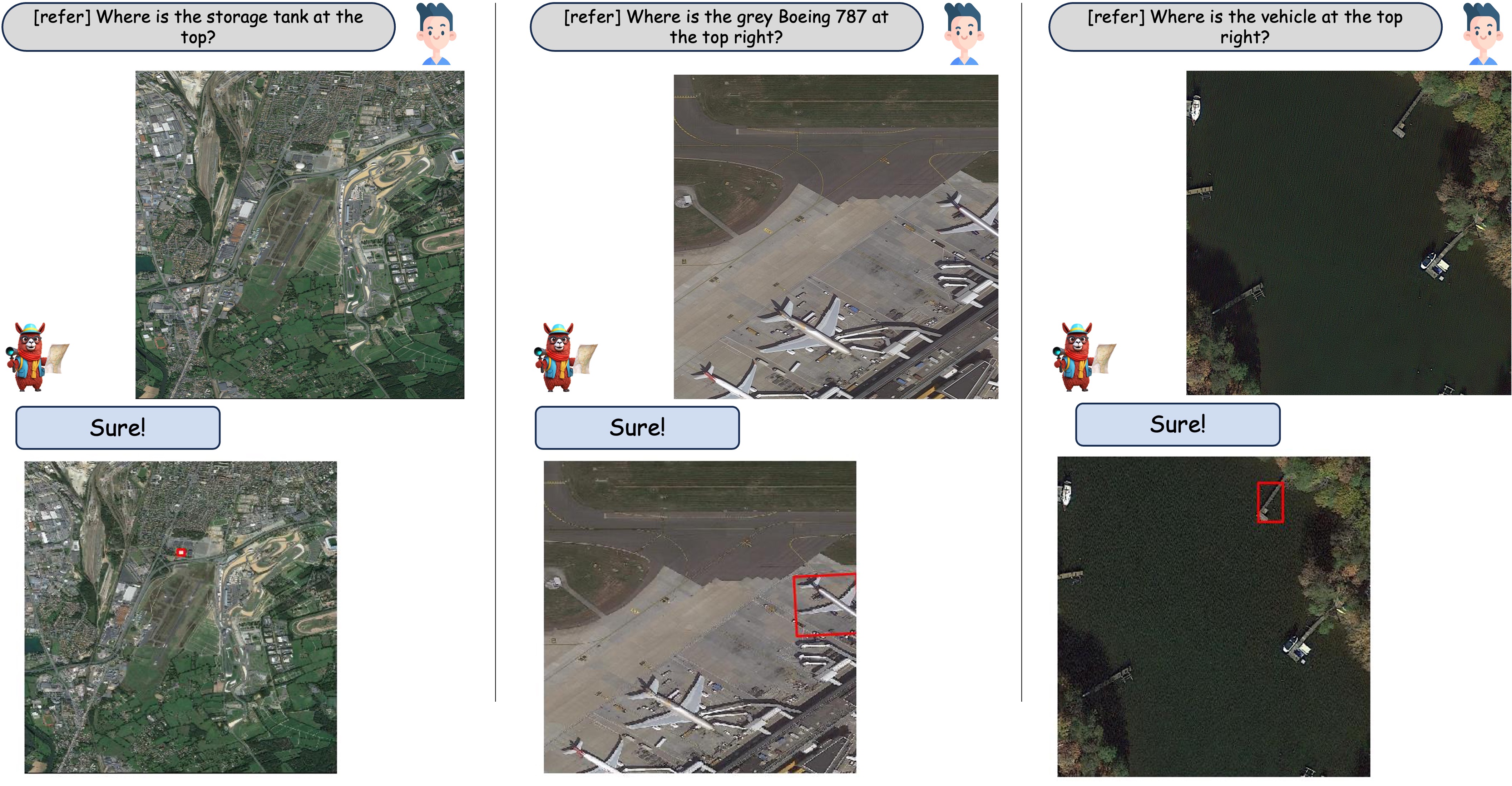
When asked about an object as a referred expression, GeoChat is able to locate object by predicting bounding boxes around it correspondingly.

| Model | Small | Medium | Large | Single-object grounding | Multi-object grounding | [refer] | [grounding] | Overall |
| MiniGPTv2 | 1.7 | 9.9 | 21.9 | 9.1 | 3.6 | 8.2 | 2.6 | 7.6 |
| GeoChat | 2.9 | 13.6 | 21.7 | 16.0 | 4.3 | 10.5 | 11.8 | 10.6 |
@misc{kuckreja2023geochat,
title={GeoChat: Grounded Large Vision-Language Model for Remote Sensing},
author={Kartik Kuckreja and Muhammad Sohail Danish and Muzammal Naseer and
Abhijit Das and Salman Khan and Fahad Shahbaz Khan},
year={2023},
eprint={2311.15826},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We are thankful to LLaVA and Vicuna for releasing their models and code as open-source contributions.