LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
LLMVoX Demo
LLMVoX: A lightweight, plug-and-play streaming TTS system for any LLM
Abstract
Recent advancements in speech-to-speech dialogue systems leverage LLMs for multimodal interactions, yet they remain hindered by fine-tuning requirements, high computational overhead, and text-speech misalignment. Existing speech-enabled LLMs often degrade conversational quality by modifying the LLM, thereby compromising its linguistic capabilities. In contrast, we propose LLMVoX, a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming TTS system that generates high-quality speech with low latency, while fully preserving the capabilities of the base LLM. Our approach achieves a significantly lower Word Error Rate compared to speech-enabled LLMs, while operating at comparable latency and UT-MOS score. By decoupling speech synthesis from LLM processing via a multi-queue token streaming system, LLMVoX supports seamless, infinite-length dialogues. Its plug-and-play design also facilitates extension to various tasks with different backbones. Furthermore, LLMVoX generalizes to new languages with only dataset adaptation, attaining a low Character Error Rate on an Arabic speech task. Additionally, we have integrated LLMVoX with a Vision-Language Model to create an omni-model with speech, text, and vision capabilities, without requiring additional multimodal training.
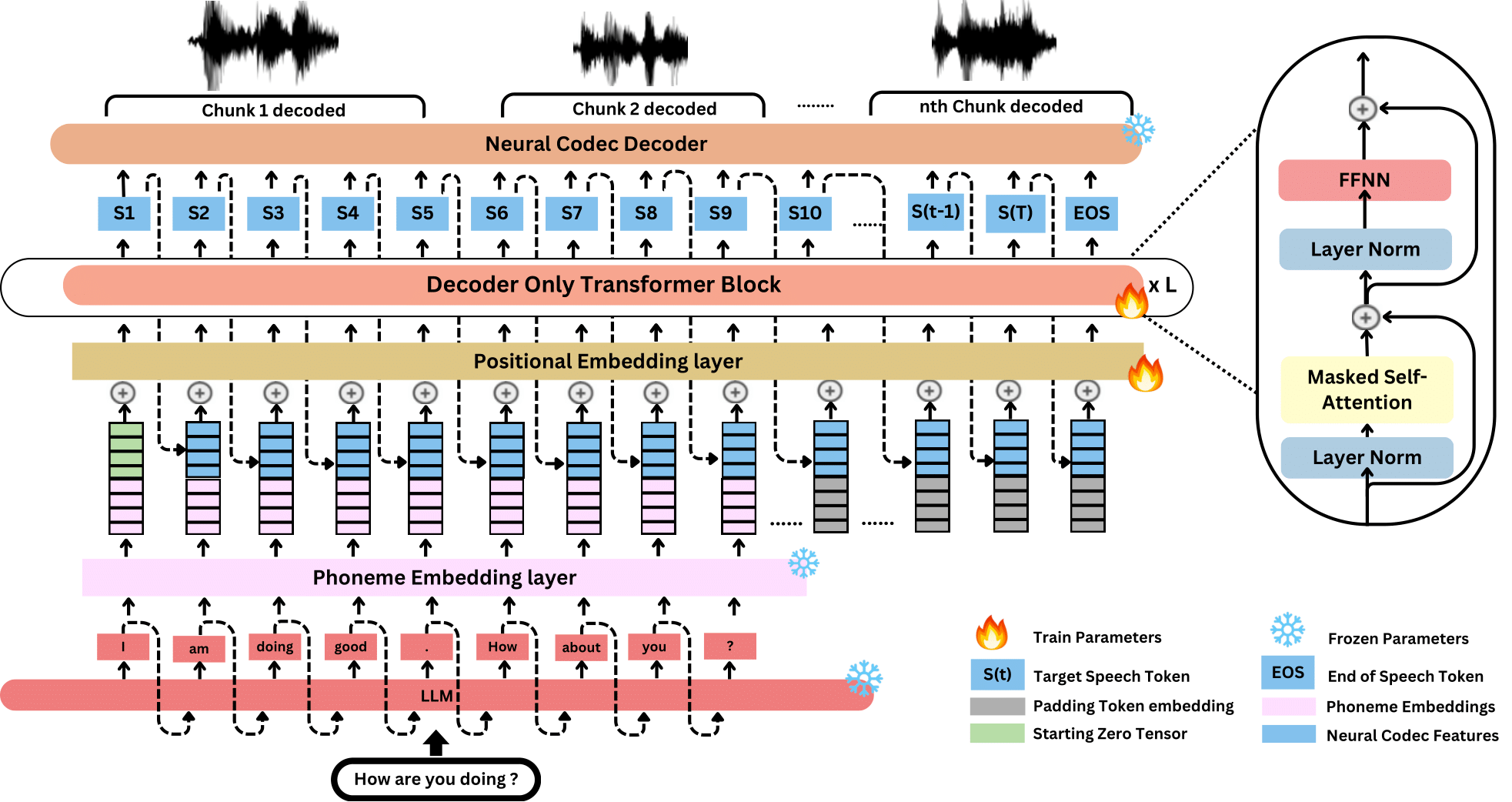
Figure 2: Overview of the proposed architecture. Text from the LLM is tokenized via a ByT5-based Grapheme-to-Phoneme(G2P) model, producing byte-level phoneme embeddings. These are concatenated with the previous speech token's feature vector, L2-normalized, and fed into a decoder-only Transformer to generate the next token.
Key Highlights
- LLM-Agnostic Design: A lightweight 30M-parameter model that preserves the base LLM's capabilities without fine-tuning or architectural modifications and offers a plug and play streaming TTS solution with any LLM
- Superior Performance: Achieves a very low Word error rate (WER) with very low latency, as low as 300 ms and high UTMOS score
- Multi-Queue Streaming: Enables continuous, low-latency speech generation for infinite-length dialogues without awkward pauses
- Language Adaptability: Generalizes to other other languages, such as Arabic with simple dataset adaptation without explicit G2P conversion
- Multimodal Integration: Seamlessly integrates with VLMs to create omni-models with speech, text, and vision capabilities
LLMVoX Demonstrations
Query:Text
Query:Video/Image,Speech
Query:Speech
Long speech generation capabilities
Multilingual adaptability
Model Performance Comparison
| Model | Base LLM | GPT-4o Score (↑) | UTMOS (↑) | WER (↓) | Latency (↓) |
|---|---|---|---|---|---|
| Whisper+LLM+XTTS | LLaMA 3.1 8B | 7.20 | 4.23 | 1.70% | 4200ms |
| Llama-Omni | LLaMA 3.1 8B | 3.64 | 3.32 | 9.18% | 220ms |
| Moshi | Helium 7B | 3.31 | 3.92 | 7.97% | 320ms |
| GLM-4-Voice | GLM-4 9B | 5.30 | 3.97 | 6.40% | 2500ms |
| Freeze-Omni | Qwen2 7B | 4.23 | 4.38 | 14.05% | 340ms |
| MiniCPM-o 2.6 | Qwen2.5 7B | 5.84 | 3.87 | 10.60% | 1200ms |
| LLMVoX (Ours) | LLaMA 3.1 8B | 6.88 | 4.05 | 3.70% | 475ms |
| LLMVoX* | LLaMA 3.1 8B | - | 3.86 | 4.1% | ~265ms |
Table 1: Performance comparison of LLMVoX with state-of-the-art speech-enabled LLMs and cascaded systems with decoding chunk size = 40.
LLMVoX*:Initial decoding chunk size = 10.
Arabic Streaming TTS Comparison
| Model | Streaming | WER (↓) | CER (↓) |
|---|---|---|---|
| XTTS | No | 0.062 | 0.017 |
| ArTST | No | 0.264 | 0.125 |
| FastPitch Arabic Finetuned | No | 0.493 | 0.153 |
| Tacotron 2 Arabic Finetuned | No | 0.663 | 0.268 |
| Tacotron 2 Arabic Finetuned | No | 0.663 | 0.268 |
| Seamless-M4t-Large | No | 0.342 | 0.145 |
| LLMVoX (Ours) | Yes | 0.234 | 0.082 |
Table 3: Arabic TTS performance comparison. LLMVoX achieves competitive error rates in a streaming setup, operating at nearly 10x faster speed compared to state-of-the-art XTTS.