 GLaMM: Grounding Large Multimodal Model
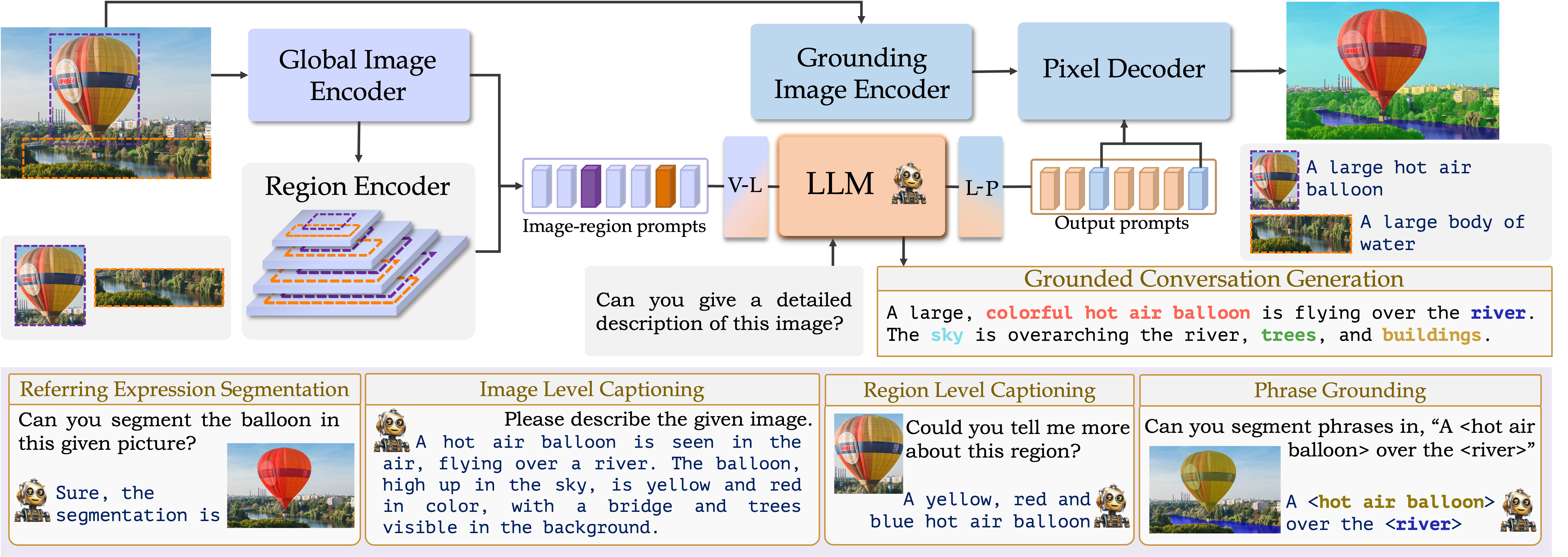
GLaMM: Grounding Large Multimodal ModelGLaMM consists of five core components to achieve visually grounded conversations: i) Global Image Encoder, ii) Region Encoder, iii) LLM, iv) Grounding Image Encoder, and v) Pixel Decoder. These components are cohesively designed to handle both textual and optional visual prompts (image level and region of interest), allowing for interaction at multiple levels of granularity, and generating grounded text responses.
 Grounding-anything Dataset (GranD)
Grounding-anything Dataset (GranD)Detailed region-level understanding requires the laborious process of collecting large-scale annotations for image regions. To alleviate the manual labelling effort, we propose an automated pipeline to annotate the large-scale Grounding-anything Dataset. Leveraging the automated pipeline with dedicated verification steps, GranD comprises 7.5M unique concepts anchored in a total of 810M regions, each with a segmentation mask.
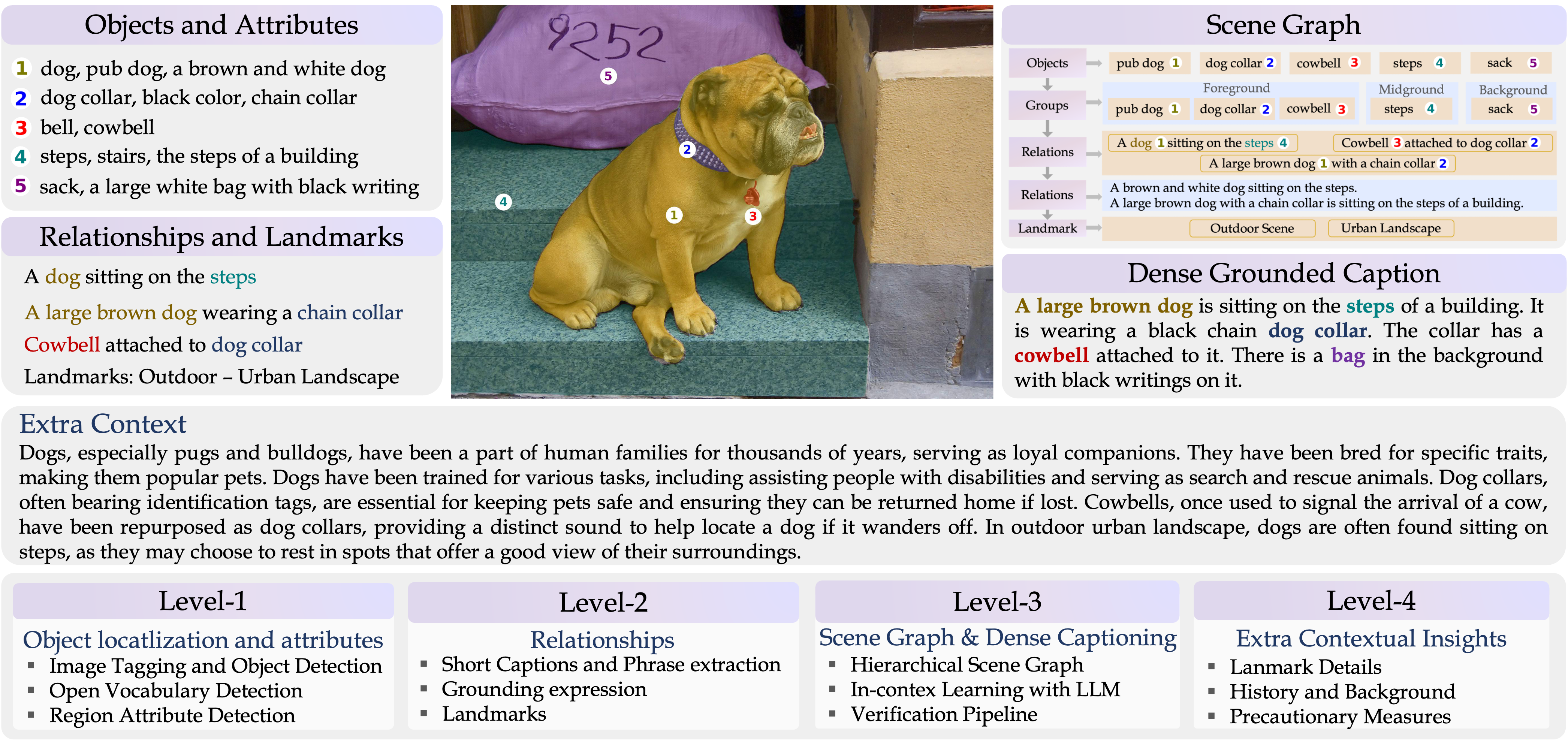
Below we present some examples of the GranD dataset. Our automated annotation pipeline provides multiple semantic tags and attributes for objects along with segmentation masks. The dense caption thoroughly describes the visual scene with part of the text grounded to the corresponding objects. The additional context provides a deeper understanding of the scene, going beyond what's observed.
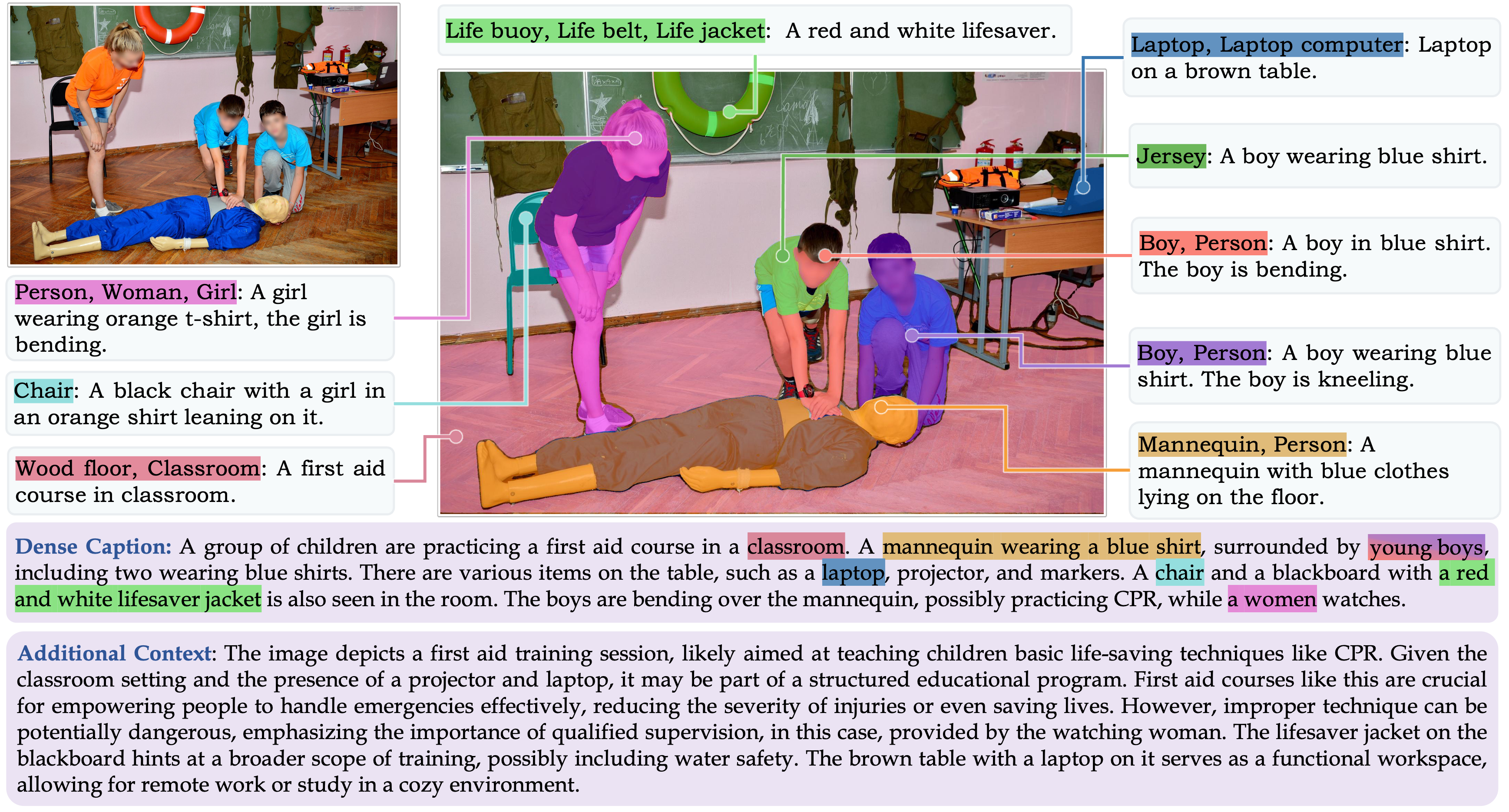

Motivated by the need for higher-quality data in fine-tuning stage, we introduce GranD-f. Explicitly designed for the GCG task, this dataset encompasses approximately 214K image-grounded text pairs. Of these, 2.6k samples are reserved for validation and 5k for testing. GranD-f comprises two primary components: one subset is manually annotated and the other subset derived by re-purposing existing open-source datasets.
 Grounded Conversation Generation (GCG)
Grounded Conversation Generation (GCG)The objective of the GCG task is to construct image-level captions with specific phrases directly tied to corresponding segmentation masks in the image. By introducing the GCG task, we bridge the gap between textual and visual understanding, thereby enhancing the model’s ability for fine-grained visual grounding alongside natural language captioning.

| Model | Validation Set | Test Set | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| METEOR | CIDEr | AP50 | mIoU | Recall | METEOR | CIDEr | AP50 | mIoU | Recall | |
| BuboGPT | 17.2 | 3.6 | 19.1 | 54.0 | 29.4 | 17.1 | 3.5 | 17.3 | 54.1 | 27.0 |
| Kosmos-2 | 16.1 | 27.6 | 17.1 | 55.6 | 28.3 | 15.8 | 27.2 | 17.2 | 56.8 | 29.0 |
| LISA* | 13.0 | 33.9 | 25.2 | 62.0 | 36.3 | 12.9 | 32.2 | 24.8 | 61.7 | 35.5 |
| GLaMM† | 15.2 | 43.1 | 28.9 | 65.8 | 39.6 | 14.6 | 37.9 | 27.2 | 64.6 | 38.0 |
| GLaMM | 16.2 | 47.2 | 30.8 | 66.3 | 41.8 | 15.8 | 43.5 | 29.2 | 65.6 | 40.8 |
Downstream ApplicationsIn this task, the model receives an image along with a text-based referring expression, to which it outputs a corresponding segmentation mask. We present quantitative results on the validation and testing sets of refCOCO, refCOCO+, and refCOCOg.

| Method | refCOCO | refCOCO+ | refCOCOg | |||||
|---|---|---|---|---|---|---|---|---|
| val | testA | testB | val | testA | testB | val(U) | test(U) | |
| CRIS (CVPR-22) | 70.5 | 73.2 | 66.1 | 65.3 | 68.1 | 53.7 | 59.9 | 60.4 |
| LAVT (CVPR-22) | 72.7 | 75.8 | 68.8 | 62.1 | 68.4 | 55.1 | 61.2 | 62.1 |
| GRES (CVPR-23) | 73.8 | 76.5 | 70.2 | 66.0 | 71.0 | 57.7 | 65.0 | 66.0 |
| X-Decoder (CVPR-23) | - | - | - | - | - | - | 64.6 | - |
| SEEM (arXiv-23) | - | - | - | - | - | - | 65.7 | - |
| LISA-7B (ZS) (arXiv-23) | 74.1 | 76.5 | 71.1 | 62.4 | 67.4 | 56.5 | 66.4 | 68.4 |
| LISA-7B (FT) (arXiv-23) | 74.9 | 79.1 | 72.3 | 65.1 | 70.8 | 58.1 | 67.9 | 70.6 |
| GLaMM (ZS) | 54.7 | 58.1 | 52.2 | 42.5 | 47.1 | 39.5 | 54.8 | 55.6 |
| GLaMM (FT) | 79.5 | 83.2 | 76.9 | 72.6 | 78.7 | 64.6 | 74.2 | 74.9 |
In this task, the goal is to generate referring expressions, or region-specific captions. The model is input an image, a designated region, and accompanying text, and is then tasked with responding to questions about the specified region. We conduct a quantitative assessment of region-level captioning on two OpenSource datasets: Visual Genome and refCOCOg. The qualitative results shown below demonstrates GLaMM's ability to adeptly generate region-specific captions, translating the intricate details from designated regions into coherent textual descriptions, enriched by its training on the comprehensive GranD dataset. This capability, combined with the inherent reasoning abilities of LLMs, enables it to tackle reasoning-based visual questions about these regions.
| Model | refCOCOg | Visual Genome | ||
|---|---|---|---|---|
| METEOR | CIDEr | METEOR | CIDEr | |
| GRIT | 15.2 | 71.6 | 17.1 | 142 |
| Kosmos-2 | 14.1 | 62.3 | - | - |
| GPT4RoI | - | - | 17.4 | 145.2 |
| GLaMM (ZS) | 15.7 | 104.0 | 17.0 | 127.0 |
| GLaMM (FT) | 16.2 | 106.0 | 19.7 | 180.5 |
GLaMM offers favourable performance when compared with recent models specialized in image captioning, as well as other LMMs. Qualitative results for image captioning are shown below.
 Conversational Style Question Answering
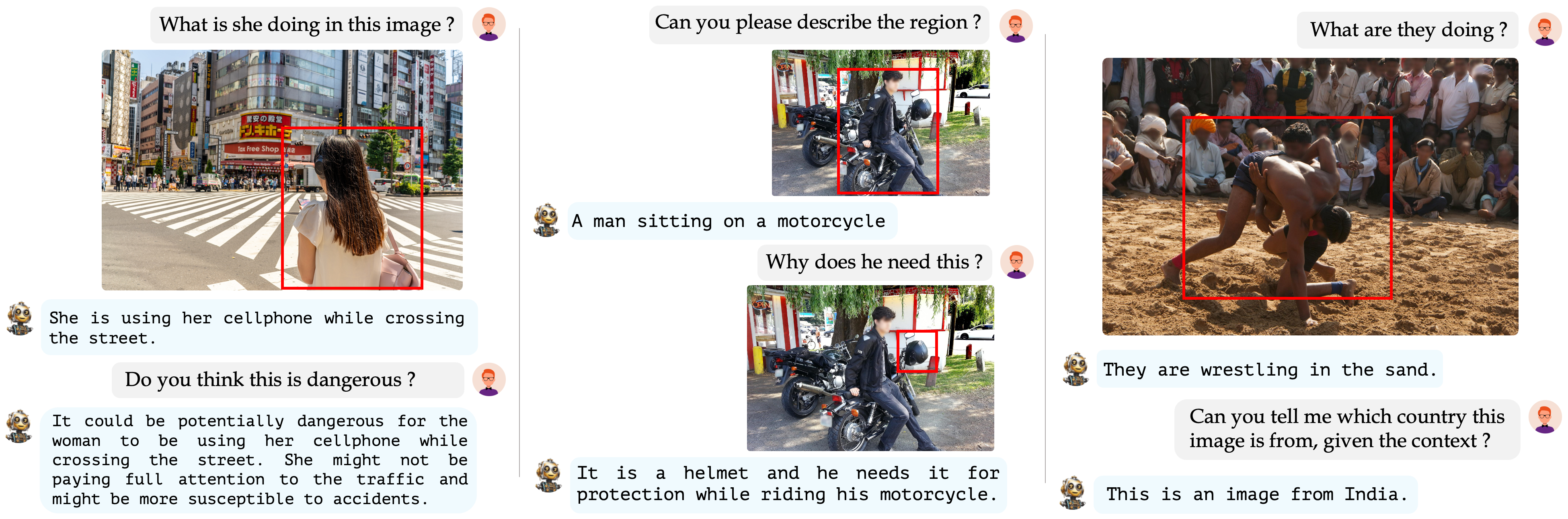
Conversational Style Question AnsweringWe evaluate our model on conversational style question answering. The qualitative results shown below showcases GLaMM engaging in multi-turn dialogues, providing detailed descriptions, addressing region-specific inquiries, and presenting grounded conversations. This effectively highlights its adaptability in intricate visual-language interactions and robustly retaining reasoning capabilities inherent to LLMs.

@article{hanoona2023GLaMM,
title={GLaMM: Pixel Grounding Large Multimodal Model},
author={Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S.},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We are thankful to LLaVA, GPT4ROI, and LISA for releasing their models and code as open-source contributions.
